February 19, 2026
- Efficient, high-bandwidth streaming of training data. Each system comes configured with a single 480 GB boot OS SSD, and four 1.92 TB SAS SSDs (7.6 TB total) configured as a RAID 0 striped volume for high-bandwidth performance.
- Multi-gpu and multi-system with GPU performance designed for HPC and Deep Learning applications. Multi-system scaling of Deep Learning computational workloads, both inside the system and between systems, to match the significant GPU performance of each system.
- The system memory capacity is higher than the GPU memory capacity to enable simplified buffer management and balance for deep learning workloads.
- Kubernetes and Docker containerized environments to easily emulate the entire software workflow and maintain portability and reproducibility.
- Jupyter notebooks for rapid development, integration with Github and HPC scheduler Slurm to distribute the workload across the system.
- Access to high-bandwidth, low-latency Briefcase storage.
ERISXdl Pricing
2026/01 Fees will no longer be applied to the DGX compute nodes.
The pricing of GPU usage has been calculated based upon the initial capital cost for the ERISXdl platform in addition to ongoing maintenance costs. Groups will be charged a flat fee of $0.01 /min (as of Nov 1st 2023) for each GPU requested in a given SLURM job. However, in order to allow for initial testing and debugging of code a free tier called the Basic partition has been created to allow users to run test jobs of up to 10min free of charge. More details about the available partitions can be found at ERISXdl: Using SLURM Job Scheduler .
A HARBOR account will be opened for the PAS group to allow its members to store customized Docker Images that are suitable for running on the dgx compute nodes in Slurm jobs. For convenience, the name of the harbor account will be the lowercase form of the PAS group name. Base images are available from Nvidia's catalog (see below) and which contains a wide selection of popular deep learning applications tuned for GPU use. To learn more about Harbor and using Docker containers on ERISXdl with Slurm, please see the articles linked below.
Please note that fees (per min of GPU time) are reviewed annually and, if necessary, will be updated from October 1st of that year.
Deep Learning Frameworks
Deep learning is a subset of AI and machine learning that uses multi-layered artificial neural networks to deliver state-of-the-art accuracy. GPU-accelerated deep learning frameworks offer flexibility to design and train custom deep neural networks and provide interfaces to commonly-used programming languages.

- Caffe/Caffe2
- Microsoft Cognitive Toolkit
- Pytorch
- TensorFlow
- mxnet
- theano
- Torch
Take a look at the NVIDIA Catalog to find all the available applications.
Support of Containerized Environments
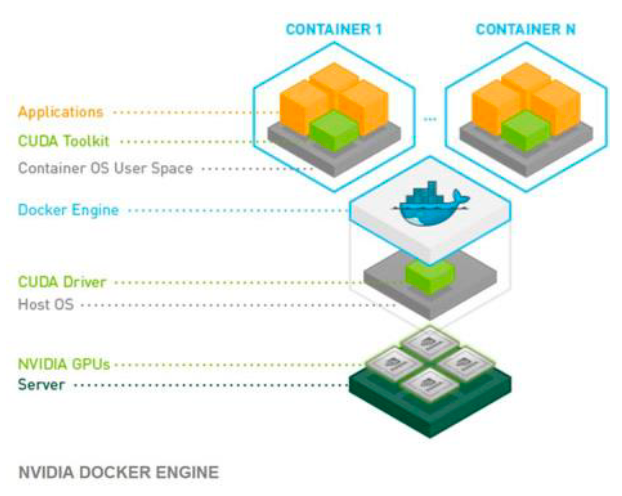
- Each deep learning framework is deployed in a separate container and where each framework can use different versions of libraries libc, cuDNN, etc., without interaction from the host operating system or other containers.
- Deep learning frameworks in the NVIDIA Docker containers are automatically configured to use parallel routines optimized for the Tesla V100 GPU architecture in the ERISXdl system.
- As deep learning frameworks are improved for performance or have bug fixes, new versions of the containers are made available in the NVIDIA Container Registry.
- Reproducibility is a key advantage of containerization and particularly in research.
- Containers require fewer system resources than traditional or hardware virtual machine environments since they don't include operating system images and are able to distribute the resources more efficiently.
Users can additionally deploy customized Docker images, possibly resulting from a collaboration, on ERISXdl and so assist in faster model development. Some care is required in these cases however to ensure that the GPUs on the compute nodes are optimally utilized.
SLURM Scheduler for Resource Management
ERISXdl employs the job scheduler Slurm to manage user access to the cluster's compute resources. Slurm is an open source, fault-tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters. In order to ensure a robust operation the Slurm controller itself runs inside a kubernetes pod with two-fold redundancy. By this means a failed Slurm control pod can rapidly regenerate on any of the three available login nodes, erisxdl1, erisxdl2 or erisxdl3. clusters.
Application Procedure for the ERISXdl platform
We first note that only Groups with fund numbers will be allowed to use Harbor and Slurm on the ERISXdl platform.
Then, the procedure for application is:
- Confirm your group has a PAS group, and if not follow the registration procedure described here, so that the PI/keygiver authorizes users of the PAS group to access the
chargedSlurm partitions. - Complete the application form for erisxdl services here
with a suitable fund number - Confirm members of the PAS group have an SciC Linux Clusters Account if they wish to use
Harbor andSlurm on ERISXdl.Please note, users registered for erisxdl services get access to the free tier called the Basic partition.
Please note, groups and their members will be removed from erisxdl/services if any of the following apply:
the provided fund number is no longer validno billable slurm jobs have been submitted for at least 2 months
Using ERISXdl
For more information about getting started with ERISXdl, please see these articles: